
Ssa!
스파르타 내일배움캠프 선형 회귀/경사 하강법/데이터 셋 분할 본문
선형 회귀와 가설, 손실함수 (Hypothesis & Cost function (Loss function))
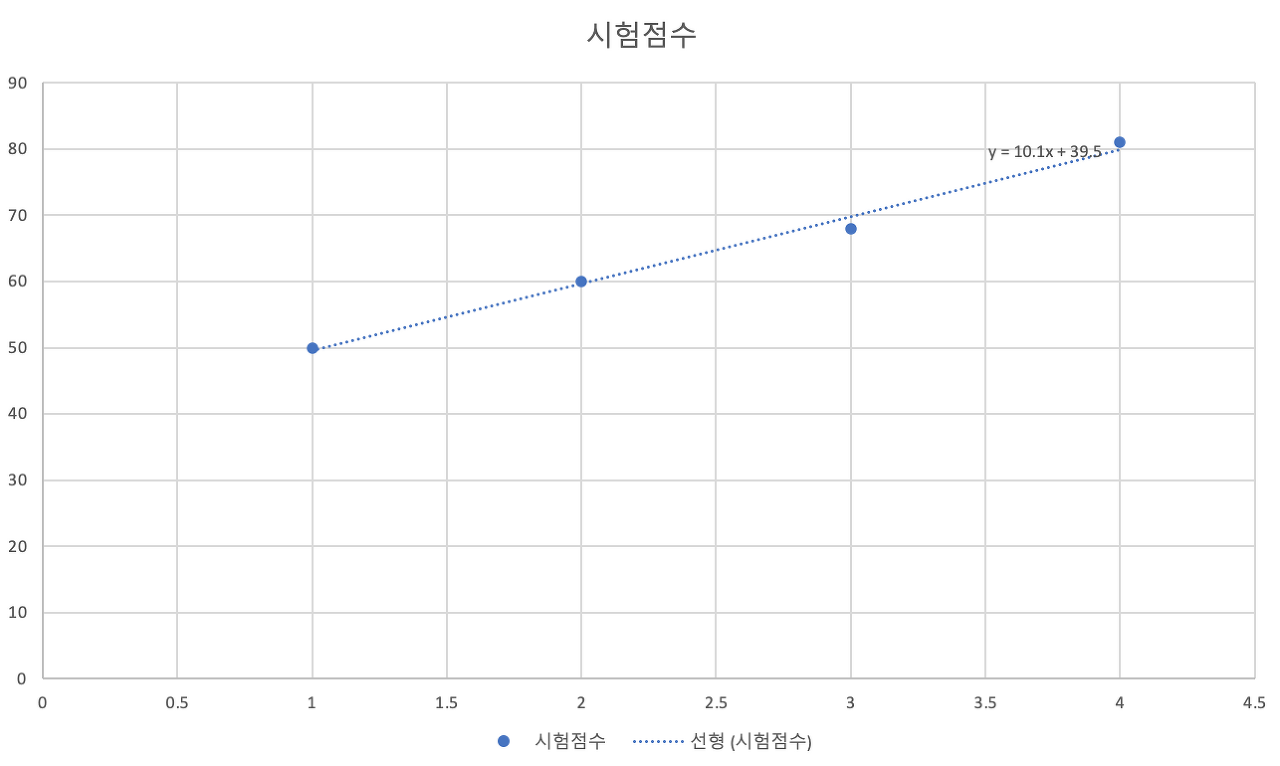
문제를 해결할 때 그래프가 있으면 가설을 세울 수 있다. 선형 모델은 H(x) = Wx + b와 같이 표현할 수 있다.
정확한 값을 예측하기 위해서 임의의 직선(가설)과 점(정답)과 거리가 가까워지도록 해야한다(= mean squared error)
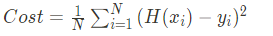
여기서 H(x)가 우리가 가정한 직석이고 y는 정답 포인트라고 했을 때 H(x)와 y의 거리(또는 차의 절대값)가 최소가 되어야 이 모델이 잘 학습되었다고 말할 수 있다.
여기서 임의로 만든 직선 H(x)를 가설이라고 하고 Cost를 손실함수(Cost or Loss function)라고 한다.
만약 여기서 더 나아가 다중 선형 회귀(Multi-variable linear regression)에 대해 배우자면
입력값이 2개 이상이 되는 문제를 선형회귀로 풀고 싶을 때 다중 선형 회귀를 사용한다.
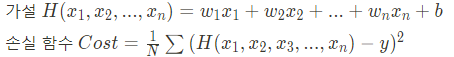
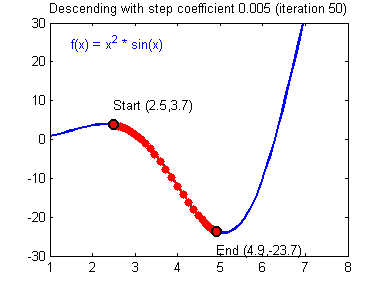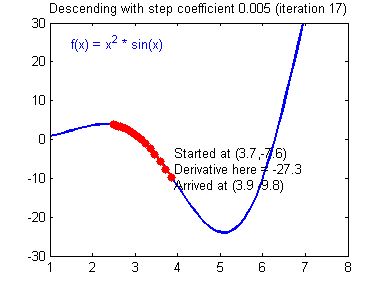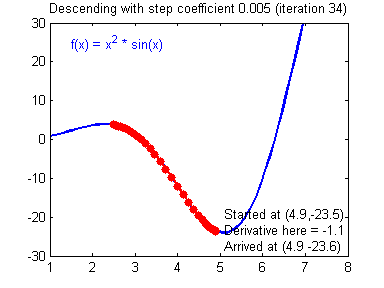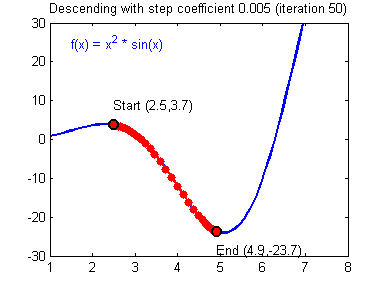
경사 하강법(Gradient descent method)

우리가 목표로 잡아야 하는 것은 손실함수를 최소화하는 것이다. 손실 함수를 최소화하는 방법은 이 그래프를 따라 점점 아래로 내려가야한다. 경사하강법이라는 방법을 써서 컴퓨터가 점진적으로 문제를 풀어간다. 처음에는 랜덤한 한점에서 시작한다. 좌우로 움직이면서 이전 값과 비교하며 작아지는지를 확인하고 한칸씩 전진하는 단위를 Learning rate라고 한다.
그 그래프의 최소점에 도달하게 된다면 학습을 종료하게 된다
만약 Learning rate가 작다면 어떻게 될까? 처음에 최소점을 찾는데까지 많은 시간이 걸린다.
아니면 Learning rate이 크다면? 최소값을 지나치고 점은 계속 진동하다가 최악의 경우에 무한대로 가버릴 수 있다. 이런 상황을 Overshooting이라고 한다.

실제 손실함수를 표현하자면 간단한 그래프로
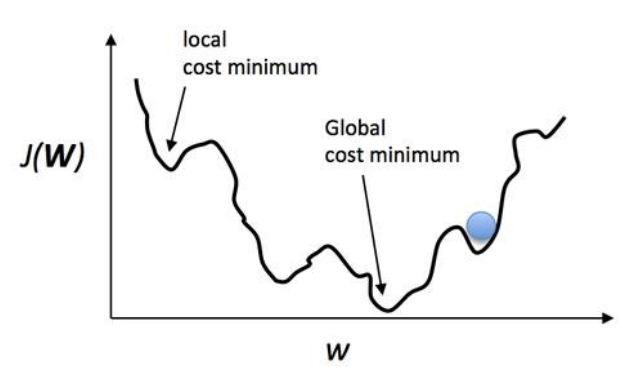
이런식으로 표현할 수 있지만 우리의 최종 목표는 Global cost minimum을 찾는 것이다. 하지만 Learning rate를 처음부터 잘못 설정할 경우 local cost minimum에 빠질 수 있어 우리가 설정하려고 했던 것보다 정확도가 낮게되버릴 수 있다.
데이터셋 분할
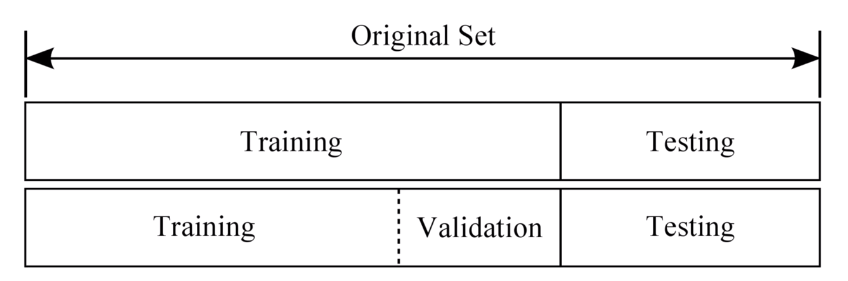
1. Tranining set : 모델을 학습시키는 용도로 사용한다.
2. Validation set: 모델의 성능을 검증하고 튜닝하는 지표의 용도로 사용한다.
3. Test set: 정답 라벨이 없는 실제 환경에서의 평가 데이터셋이다(가장 중요!!!)
'CS > 머신러닝' 카테고리의 다른 글
| 스파르타 내일배움캠프 머신러닝에서의 전처리 (0) | 2022.10.11 |
|---|---|
| 스파르타 내일배움캠프 다양한 머신러닝 모델 (0) | 2022.10.11 |
| 스파르타 내일배움캠프 다항 논리 회귀, Softmax 함수와 손실함수 (0) | 2022.10.11 |
| 스파르타 내일배움캠프 논리 회귀, 가설, 손실함수 (1) | 2022.10.11 |
| 스파르타 내일배움캠프 머신러닝이란? (2) | 2022.10.07 |



